AI 模型设置
配置 TalkCody 的 AI 模型,选择适合您需求的模型
模型类型概述
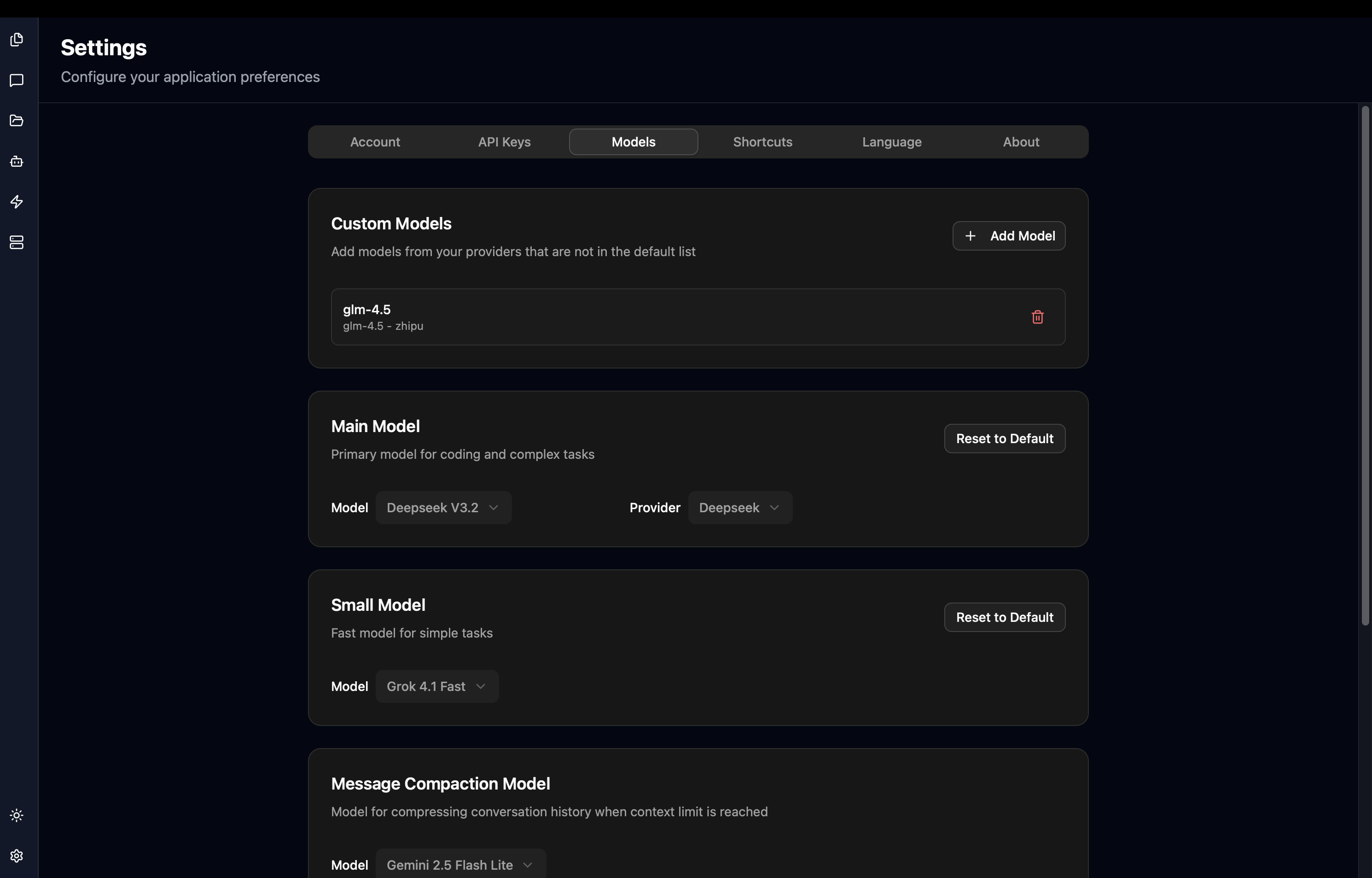
TalkCody 支持为不同的任务配置不同的 AI 模型,以优化性能和成本:
| 模型类型 | 用途 | 默认模型 |
|---|---|---|
| 主模型 | 复杂推理、编码和分析任务 | Claude Haiku |
| 小模型 | 简单任务和快速响应 | Gemini 2.5 Flash Lite |
| 消息压缩模型 | 压缩对话历史以节省 Token | Gemini 2.5 Flash Lite |
| 图像生成模型 | 从文本描述生成图像 | Nano Banana Pro |
| 语音转文字模型 | 将语音/音频转换为文字 | Scribe V2 Realtime |
每种模型类型都有默认值。如果您不进行设置,TalkCody 会自动使用默认模型。
设置模型
设置路径: 设置 → 模型设置
主模型 (Main Model)
主模型用于处理复杂的推理、编码和分析任务。这是 TalkCody 的核心模型,建议选择能力较强的模型。
推荐模型:
- Claude 4.5 Sonnet or Claude 4.5 Opus(推理能力强)
- GPT 5.1 Codex(解决 bug 能力强)
- Gemini 3 Pro(前端开发能力强)
小模型 (Small Model)
小模型用于处理简单任务和需要快速响应的场景,如代码补全建议、简单问答等。
推荐模型:
- Gemini 2.5 Flash Lite(速度快、成本低)
- Grok Code Fast(适合代码相关任务)
- DeepSeek V3 (Agent 能力出色)
使用小模型可以显著降低 API 成本,同时保持较好的响应速度。
消息压缩模型 (Message Compaction)
当对话历史过长时,TalkCody 会使用此模型压缩历史消息,以节省 Token 并保持上下文相关性。
推荐模型:
- Gemini 2.5 Flash Lite(成本低、速度快)
图像生成模型 (Image Generator)
用于从文本描述生成图像的模型。
支持的模型:
- DALL-E 3(OpenAI)
- Nano Banana Pro(Banana)
- 其他支持图像输出的模型
只有支持图像输出的模型才会出现在图像生成模型的选择列表中。
语音转文字模型 (Transcription)
用于将语音或音频文件转换为文字的模型。
支持的模型:
- Scribe V2 Realtime(Eleven Labs,实时转写)
- Whisper(OpenAI)
只有支持音频输入的模型才会出现在语音转文字模型的选择列表中。
选择提供商
当同一个模型可以通过多个提供商访问时(例如通过 OpenRouter 和官方 API),您可以选择使用哪个提供商。
选择模型
在模型下拉列表中选择您想使用的模型。
选择提供商
如果该模型支持多个提供商,会出现「提供商」下拉列表。选择您偏好的提供商。
提供商选择建议:
- 官方 API: 稳定性最好,功能最完整
- OpenRouter: 价格可能更优惠,统一管理多个模型
- Vercel AI Gateway: 适合已使用 Vercel 服务的用户
不同提供商的定价和速度可能不同。您可以根据自己的需求选择最适合的提供商。
添加自定义模型
如果 TalkCody 内置的模型列表中没有您需要的模型,您可以添加自定义模型。
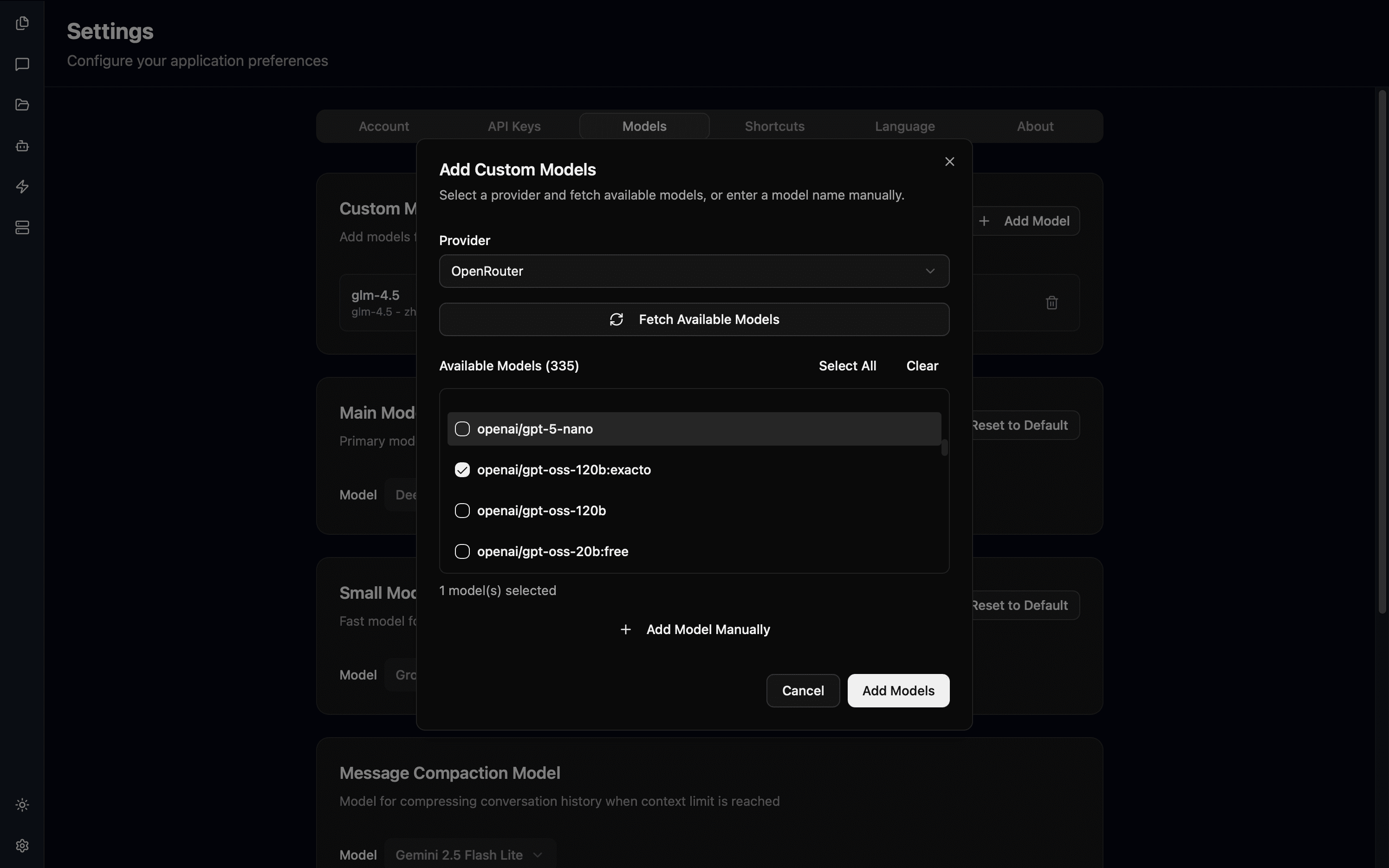
打开添加对话框
在模型设置页面,点击「自定义模型」部分右侧的「添加模型」按钮。
选择提供商
在弹出的对话框中,选择模型所属的提供商(如 OpenAI、Ollama、LM Studio 等)。
获取或输入模型
方式一:自动获取模型列表
对于支持模型列表 API 的提供商(如 Ollama、LM Studio、OpenAI):
- 点击「获取模型」按钮
- 系统会自动获取该提供商的可用模型列表
- 勾选您想添加的模型
- 点击「添加模型」
方式二:手动输入模型名称
对于不支持模型列表获取的提供商,或者您知道确切的模型名称:
- 在「模型名称」输入框中输入模型 ID
- 点击「添加模型」
添加的自定义模型会出现在所有模型选择列表中,您可以将其设置为任意模型类型。
常见问题
模型列表为空怎么办?
确保您已经在「API 密钥」设置中配置了至少一个有效的 API 密钥。模型列表只会显示已配置提供商的可用模型。
为什么某些模型不在图像生成列表中?
图像生成模型列表只显示支持图像输出的模型。普通的文本模型不会出现在此列表中。
自定义模型添加后不显示?
- 确保提供商的 API 密钥已正确配置
- 尝试刷新页面
- 检查模型 ID 是否正确(区分大小写)